March 18th, 2024
A defining feature of an asynchronous operation is that it is cancellable.
March 5th, 2024
Good programing is more about good judgment than anything else.
Note posted on Tuesday, March 5, 2024 2:29 PM CST - link
The Interaction State Primitive
I've been developing UI's in some form or another for about 25 years. It's taken nearly that long to realize the basic primitive of dynamic UI's: what I call the "Interaction State" primitive. The Interaction State primitive has these rules:
- The current state of the property can be accessed via a normal get accessor. In Java, this might be a method with a signature like
T getValue(). Sometimes this is called a snapshot, but I prefer the more direct terminology of state. In a language with more syntactical magic available, it can be done via something like a get accessor. - Its value can be updated via a normal set accessor. In Java, this might look like
setValue(T value). Again, in other languages, syntax magic can make the write access more terse. - Updates to the property's state are observable. Below, I will cheat and use the ReactiveX flavors to achieve this.
setValue(T value)only notifies observers the value is updated when the new value is not equal to the existing value. This should follow normal equality rules of the language.
I am not the first to make this observation; KnockoutJS, which I used c.a. 2014, had observables in Javascript, and Rx.Net and other ReactiveX flavors have been around for quite some time, with the BehaviorSubject<T>, which has the above semantics, but with slightly contorted syntax. However, in my opinion, all of these languages and libraries don't make it plain that these are the rules they're following. Perhaps the authors of these API's think these rules are obvious and don't need to be broadcast. However, these rules weren't made plain to me until I came across the StateFlow type in Kotlin: upon observing it's simplicity, the lack of too much magic or layers of obfuscation, this raw form of the Interaction State primitive made it all obvious to me.
What benefits does this Interaction State primitive give?
- When used as the main representation of the data state in a View Model, they're easily testable; the current state of the property can be taken just by calling
getValue(), and if you want to validate how the property changes over time, you can easily do that too. - When the observable portion is implemented using something like the Reactive extensions, you can observe its value over time with endless numbers of operators. Using something very generic like Reactive extensions instead of something like
StateFlowleaves you very free of any assumptions made about the runtime or environment; for example, you don't have to mess with coroutine contexts or anything like that. - Integrates very nicely with dynamic UI frameworks; React obviously has its state variables, Jetpack Compose has the magical
stateOfandmutableStateOf, and C# has theINotifyPropertyChangedmagical interface, and the Interaction State primitive can integrate very nicely with all of them! It also integrates well with something like WinForms.
I want to show some examples of how this primitive can be used in different languages, with a fairly simple use case: given expenses and incomes, display the networth.
Kotlin and Jetpack Compose
Here's an example in Kotlin, integrating with Jetpack Compose:
// The read-only interface for the Interaction State Primitive
abstract class InteractionState<T> : Observable<NullBox<T>>() {
abstract val value: T
}
// A mutable implementation of the read-only interface for the Interaction State Primitive.
class MutableInteractionState<T>(private val initialValue: T) : InteractionState<T>() {
// RxJava has the unfortunate design decision of nulls not being allowed as values, so we
// box the value to allow nulls.
private val behaviorSubject = BehaviorSubject.createDefault(NullBox(initialValue))
override var value: T
get() = behaviorSubject.value?.value ?: initialValue
set(value) {
if (behaviorSubject.value != value)
behaviorSubject.onNext(NullBox(value))
}
override fun subscribeActual(observer: Observer<in NullBox<T>>?) {
behaviorSubject.safeSubscribe(observer)
}
fun asReadOnly(): InteractionState<T> = this
}
class LiftedInteractionState<T: Any>(source: Observable<T>, private val initialValue: T) : InteractionState<T>(), AutoCloseable {
private val behaviorSubject = BehaviorSubject.createDefault(NullBox(initialValue))
private val subscription = source.distinctUntilChanged().subscribe { behaviorSubject.onNext(NullBox(it)) }
override val value: T
get() = behaviorSubject.value?.value ?: initialValue
override fun subscribeActual(observer: Observer<in NullBox<T>>?) {
behaviorSubject.safeSubscribe(observer)
}
override fun close() {
subscription.dispose()
}
}
class MoneyViewModel(accountManager: ManageAccounts) : ViewModel() {
val expenses = MutableInteractionState(0.0);
val income = MutableInteractionState(0.0);
val networth = LiftedInteractionState(
Observable.combineLatest(expenses, income).map { expenses, income -> income - expenses },
0.0);
suspend fun loadAccount(int accountId) {
var account = accountManager.loadAccount(accountId);
expenses.Value = account.Expenses;
income.Value = account.Income;
}
}
// easily map MutableInteractionState to mutableStateOf(...)
@Composable
fun <T, S : MutableInteractionState<T>> S.subscribeAsMutableState(
context: CoroutineContext = EmptyCoroutineContext
): MutableState<T> {
val state = remember { mutableStateOf(value) }
DisposableEffect(key1 = this) {
val disposable = subscribe { state.value = it.value }
onDispose {
disposable.dispose()
}
}
LaunchedEffect(key1 = this) {
value = state.value
if (context == EmptyCoroutineContext) {
snapshotFlow { state.value }.collect {
value = it
}
} else withContext(context) {
snapshotFlow { state.value }.collect {
value = it
}
}
}
return state
}
// The Compose view
fun MoneyView(viewModel: MoneyViewModel) {
with (viewModel){
var expensesState by expenses.subscribeAsMutableState()
StandardTextField(
placeholder = stringResource("Debit"),
value = expensesState,
onValueChange = { expensesState = it }
)
var incomeState by income.subscribeAsMutableState()
StandardTextField(
placeholder = stringResource("Credit"),
value = incomeState,
onValueChange = { incomeState = it }
)
val networth by networth.subscribeAsState()
Text(networth);
}
}
Typescript and React
Here's my usage in Typescript/React:
// Build up the type definitions
export interface InteractionState<State> extends Subscribable<State> {
get value(): State;
}
export interface UpdatableInteractionState<State> extends InteractionState<State> {
set value(state: State);
}
// With Typescript, we have the advantage that we can just inherit from the existing `BehaviorSubject` and here
// make `value()` read-only via interface. Of course it's not enforced in the runtime, but it's good enough for us.
class MutableInteractionState<T> extends BehaviorSubject<T> implements UpdatableInteractionState<T> {
constructor(initialValue: T) {
super(initialValue);
}
set value(value: T) {
this.next(value);
}
}
class LiftedInteractionState<T> extends BehaviorSubject<T> implements InteractionState<T> {
constructor(observable: Observable<T>, initialValue: T) {
super(initialValue);
observable.subscribe(this);
}
}
export function liftInteractionState<T>(observable: Observable<T>, initialValue: T): Observable<T> & InteractionState<T> & SubscriptionLike {
return new LiftedInteractionState(observable, initialValue);
}
export function mutableInteractionState<T>(initialValue: T): Observable<T> & UpdatableInteractionState<T> & SubscriptionLike {
return new MutableInteractionState(initialValue);
}
export function useInteractionState<T>(interactionState: InteractionState<T>): T {
const [state, setState] = React.useState(interactionState.value);
React.useEffect(() => {
const sub = interactionState.subscribe({ next: setState });
return () => sub.unsubscribe();
}, [interactionState]);
return state;
}
export function useMutableInteractionState<T>(interactionState: UpdatableInteractionState<T>): [T, Dispatch<SetStateAction<T>>] {
const state = useInteractionState(interactionState);
return [
state,
(stateOrAction: SetStateAction<T>) => {
if (stateOrAction instanceof Function) {
interactionState.value = stateOrAction(interactionState.value);
return;
}
interactionState.value = stateOrAction;
}];
}
export class MoneyViewModel {
readonly income = mutableInteractionState(0);
readonly expenses = mutableInteractionState(0);
readonly networth = liftInteractionState(
combineLatest([this.income, this.expenses]).pipe(map(([i, e]) => i - e)),
0);
}
const vm = new MoneyViewModel();
export function MoneyView() {
const income = useInteractionState(vm.income);
const expenses = useInteractionState(vm.expenses);
const networth = useInteractionState(vm.networth);
return <div>
<input type="text" value={income} onChange={e => vm.income.value = Number.parseFloat(e.target.value)}/>
<input type="text" value={expenses} onChange={e => vm.expenses.value = Number.parseFloat(e.target.value)}/>
<div>
<h3>Networth:</h3>
<p>{networth}</p>
</div>
</div>;
}
C# and WPF
interface IInteractionState<T> : IObservable<T>
{
public T Value { get; }
}
// Implementing INotifyPropertyChanged as well allows it to be used with WPF/XAML bindings
class MutableInteractionState<T> : IReadOnlyObservableProperty<T>, INotifyPropertyChanged, IDisposable
{
private readonly BehaviorSubject<T> subject;
public event PropertyChangedEventHandler PropertyChanged;
public MutableInteractionState(T initialValue)
{
subject = new BehaviorSubject<T>(initialValue);
}
public T Value
{
get => subject.Value;
set
{
if (!EqualityComparer<T>.Default.Equals(value, subject.Value))
{
subject.OnNext(value);
PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(nameof(Value)));
}
}
}
public IDisposable Subscribe(IObserver<T> observer) => subject.Subscribe(observer);
public override void Dispose() => subject.Dispose();
}
// A read-only observable
class LiftedInteractionState<T> : IReadOnlyObservableProperty<T>, INotifyPropertyChanged
{
private readonly BehaviorSubject<T> subject;
private readonly IDisposable sourceSub;
public event PropertyChangedEventHandler PropertyChanged;
public LiftedInteractionState(IObservable<T> source, T initialValue)
{
subject = new BehaviorSubject<T>(initialValue);
sourceSub = source.Subscribe(v => Value = v);
}
public T Value
{
get => subject.Value;
private set
{
if (!EqualityComparer<T>.Default.Equals(value, subject.Value))
{
subject.OnNext(value);
PropertyChanged?.Invoke(this, new PropertyChangedEventArgs(nameof(Value)));
}
}
}
public IDisposable Subscribe(IObserver<T> observer) => subject.Subscribe(observer);
public override void Dispose()
{
sourceSub.Dispose();
subject.Dispose();
}
}
class MoneyViewModel
{
private readonly IAccountManager accountManager;
public MutableInteractionState<decimal> Debit { get; } = new(0);
public MutableInteractionState<decimal> Credit { get; } = new(0);
public IInteractionState<decimal> Networth;
public MoneyViewModel(IAccountManager accountManager)
{
this.accountManager = accountManager;
this.Total = new LiftedInteractionState<decimal>(
this.Credit.CombineLatest(this.Debit).Select(tuple =>
{
var (credit, debit) = tuple;
return credit - debit;
}),
0);
}
public async Task LoadAccount(int accountId) {
var account = await accountManager.LoadAccount(accountId);
Debit.Value = account.Debit;
Credit.Value = account.Credit;
}
}
<Window>
<Grid>
<TextField Value={Binding Debit.Value} />
<TextField Value={Binding Credit.Value} />
<TextLabel Value={Binding Networth.Value} />
</Grid>
</Window>
In my opinion, removing the obscurity around this primitive has a similar effect to understanding the Promise; it opens up and simplifies a whole class of programming problems: with the Promise, a single definition is wrapped around building asynchronous functions and receiving their results, likewise, for the "Interaction State" primitive, a single definition is given to making a UI that reacts to inputs agnostic of the source; in other words, regardless of whether the UI needs to respond to user input or the UI needs to respond to asynchronous calls, the situation will be handled in the same way by the "Interaction State" primitive. It also enables a programmer to use it for purposes beyond what the implementations above restrict the user to; for example, I've used the Kotlin implementation in both Android XML views and Jetpack Compose, likewise, I've used the C# implementation for common code between WinForms views and WPF views. This allows my view models to remain stable, while only the decoration is updated with new binding syntax.
Note posted on Saturday, January 27, 2024 11:47 AM CST - link
November 29th, 2023
A core component of learning is separating signal from noise on a given subject. The corollary is that a core component of teaching a subject is informing the student which parts are noise; the signal falls out from this.
November 1st, 2023
Having dealt with C# DLL hell for years, and then going through the equally hellish dotnet HttpClient fiascos, and now struggling with adopting ES modules in a Typescript library, I am beginning to believe that Microsoft has a department focused on making module resolution a living hell for anyone who uses their tools.
Note posted on Wednesday, November 8, 2023 1:17 PM CST - link
Solid Freeform 2023 Notes
From August 14-16, 2023 I attended an academic conference on 3D printing research, below are my notes.
Technion Additive Manufacturing Center
- Current geometric design pardigm ha sbeen with us for over a decade
- V-rep operations:
- Filleting and rouding
- Mixed symbolic/numeric computations over multivariate (and V-rep) splines
- https://csaws.cs.technion.ac.il/~gershon/irit
In-Situ Process Monitoring in AM
Michael J. Heiden
Purpose, Motivation
- Failure mode analysis (ie spike in oxygen)
- Reduce coupon inspection
- Runs in parallel with the build process
Detection Methods and Processes
- Optical IR
- Use the Peregrine machine learning model from Oakridge
- Use multi-modal data (thermal imaging/thermography, high speed cameras, spectroscopy, acoustic monitoring)
Using the Data to Create Useful 3D Digital Twins
- Show discrepancies between what is supposed to be printed and the actual
Future Targets
- Real time monitoring
- Closed lop control for defect correction (this is what we do!)
Machine Learning Applied to Process Monitoring for Laser Hot Wire Directed Energy Deposition
Carnegie Mellon University
Comparison with Laser Powder Bed Fusion
- Under acceptable conditions, melt pools are not stable
- Monitoring of rare unwanted events such as spatter requires significant ML traning (1k-10k hand-labeled images)
Laser Hot Wire Additive Manufacturing
- Well behaved melt pools under normal conditions
- Can monitor entire buildds in real time
- Approach: detect unsteady behavior of the melt pool, don't attempt to learn the appearnce of irregular events
Methodology
- Many flaws exist across multiple frames, so a time dependent analysis is beneficial
- Long Short-Term Memory networks are able to learn time dependencies in video data
- Use previous frames to predict future frames (about 10-20 frames of past history)
- Capture a regularity scorePredicition: within 5-10 years we will see fully sensed and automated DED systems
Known Flaw Types
- Stable Deposition
- Melt pool oscillation
- Arcing
- Wire stubbing
- Wire dripping
Summary and Conclusions
- ML model detects unsteady behavior, which is indicative of process instability (unlike LBPF)
- Prediction is that DED systems will be deployed with fully automatic quality control in next 5-10 years
Area Printing
- Area printing is stamping on the powderbed
- Seurat is the company that developed this technology
Rethinking Additive Manufacturing
- DfAM transcends disciplinary boundaries
- Traditional manufacturing informs our design sensibilities
- Evaluate design using consensual design techniques
- DfAM increases as experience increases
- Restrictive DfAM: "Can we print it"
- Opportunistic DfAM: "Should we print it"
- Unlearning requires designers to identify good DfAM solutions
- VR can help with DfAM
- Use VR for simulating a printer in test?
- Probably not super beneficial for our needs
Co-deisgn of 3D Printing
- You cannot monitor your way out of trouble: need all the insights possible from in-situ and operando monitoring.
- In aircraft manufacturing: "Anything that allows you to gain efficiency is worth the manufacturing cost"
- Diffusion Modeling is not sufficient for AM Heat Exchangers
- Use heat exchangers used with solar energy?
- Alternate technology: diffusion bonding
- Improved heat exchangers reduces defects?
Physical Validation of Job Placement Optimization in Cooperative 3D Printing
- Traditional vs Cooperative 3D printing
- Traditional: gantry systems
- Limited in scalability and flexibility
- Partitioning Strategy: Chunking
- First chunk into layers (Z-Chunking)
- XY-Chunking: chunk adjacent chunks at an angle to facilitate bonding of chunks
- Use grid search algorithm (A* Path Planning) to plan robot movement
- If there are two robots that are going to take a path at the same time, apply a conflict avoidance algorithm
- AMBOTS C3DP
- When a robot moves to a new location, it requires manual calibration
Time Optimal Path Planning for Heterogenous Robots in Swarm Manufacturing
- Continuous spatial profile with arbitrary robot gemoetry that includes orienatation
- Dynamic environment with arbitrary number of obstacles
- Time-optimal solution for multiple agents
- Projecting Dynamic Obstacles
- Use "safe intervals" to reduce number of computations
- Based on safe intervals, split the configurations based on what has more than one safe interval
- Limitations:
- Does not make real-time adjustments
- Truly centralized optimal planning scales exponentially with the number of agents
- Open questions:
- How does shape discretizaiton impact solution quality?
- What is the upper number of agents before it is too computationally expensive?
Layer Wise Prediction of Microstructural Evolution
- Predict grain size and melt-pool depth using thermal model features
- As structure grows, cooling rate decreases
- Prediction using physics-guided machine learning (SVM models)
- Predict Meltpool Depth
- Not inuitively explained by process parameters
- Thermal Feature Correlate to Grain Size
- Grain size predicted with 90% F-Score
- Predict Meltpool Depth
- Cooling rate also decreases with heat build-up
Post Superficial Temperature Monitoring During Additive Manufacturing
- CNN goal is to produce predicted temperature of build
- Best results come from combining a machine learning model, in situ monitoring, and sensors
- Normal Data + Wall Simulation as inputs gives best ML performance on experimental data
- In Situ Sensors + ML models as a "Digital Twin" of how the part will be produced
Optimal Control of Wire DED Systems
- Modeling of a dynamic system usually using ODE
- Optimal Control Theory - https://en.wikipedia.org/wiki/Optimal_control
Framework for Physics Guided Machine Learning
- Process variations are high in AM
- PSP: Process-structure-property
PSP Linkages for In-situ Data
- Predictive Melt-pool Modeling
- Multi-layer model produced best results
- Predictive Pore-structure Model
- Predictive Surface-height Model
AI Driven In-Situ Monitoring
Intrinsic Keyhole Oscillation
Keyhole: a puncture in the powderbed that leads to an unexpected cavity ("keyhole pore") in the powderbed
- Combine X-Ray imaging and Thermal Imaging
- Intrinsic Keyhole Oscillation
- Surface tension and coil pressure
- Liquid flow on the outside of the meltpool increases keyhole size
- Lower than 30KHz
- Perturbative Keyhole Oscillation
- Greater than 40KHz
Gradient-weighted Class Activation Mapping (Grad CAM)
- Predict where keyholes will form using an ML model, avoiding further X-Ray synchotron experiments
- An input to the trained model is a simulation of the build
PRISM: Process Parameter Optimization for Selective Manufacturing
- Goldilocks zone:
- Not enough: lack of fusion
- Too much: keyhole formulation
- Use machine learning to determine proper process parameters!
- Goal is to achieve high density, assume density is a surrogate for:
- CTE (Coefficient of thermal expansion)
- Elastic modulus
- Strength
- Toughness
- Data will be published and open source
- ML Driven Design of Experiment
- Latin hyper cube sample generation
- Predict Printability using tree algorithm (bounds determined by expert)
- Predict density using tree algorithms (XGBoost)
- Select candidates: diversity (determined by L2 distance), quality, and random sleection
- Used FLAML to automate experimentation
- Would probably need to re-train per material type
FAIR Knowledge Management System for Additive Manufacturing
- AMMD.nist.gov, AMBench2022.nist.gov
- ASTM F42 - working group developing data models to represent AM
Unconventional Data Sources for Market Intelligence
- Aachen Center for AM
- Market intelligence uses external data over internal data (patent databases, social media, etc.)
- Databases used for research: Amadeus, LinkedIn, Scopus
Digital Twins
- Part qualification is manual and slow
- Can digital twins help understand the process to manufacturing property map?
- Direct Ink Write
- Using robotic automation to generate large amounts of parts and data
Executable for Avant Garde Laser Exposure (EAGLE)
- Common command interfaces
- Ability to support any input file
- Plugin support
- Process Buckets
- Limited interference with machine
- Common Build Data Storage
- SQL Database on machine or network
- Print Process Flow:
- Pre-Process
- Layer Process:
- Verify -> Scan -> Characterize -> Recoat
- Post-Process
- EAGLE is written in Rust and Javascript using Tauri
- Designed to support print files > 100GB
Direction not intention determines destination
In-Situ Monitoring Using Neutron Rays
- Neutrons have high penetration in metals
- Different contrast from X-Rays
- Phase evolution
- In-Situ Laser Metal Deposition
- Completmentary to lab and synchotron experiments
- In-Beamline Strain Measurement
- Neutrons are non-destructive, tri-axial, and sub-surface
- Additive has a much wider distribution of gamma prime and gamma double prime sizes
X-Ray Compute Tomagrphy
- Determine powder size because that's always going to be stuck on the surface
- Could minimum powder size (and laser amplitude?) define minimum defects size?
SATURN
SCT and MPM Data
- Lack of fusion and keyhole are two major issues (laser power)
- Rnadom forest prediction works with decent acccuracy
- U-net model?
- Some defects will heal automatically, and don't need to be treated
- Non-balanced gain control introduces saturation in the photodiodes
- OEM gives a graphical representation of the data, not a tabular or formatted version
- Photodiodes operate at >11MHz
- Sensor captures images at 400um resolution
Intelligent Process Control
- Using FPGA to provide faster response times
- Goal is to catch a defect within the transient state (10-20us), they've (potentially) achieved nanosecond response times
High precision measurement of Melt Pools
- FPS of 40,000
- Resolution: 896 x 176 pixels
End-to-End AI Models for Error Detection
- Current issue - solutions are not general
- Matta (Cambridge company), Grey-1 AI Copilot for AM
- Multi-head residual attention convolutional neural network:
- Develops its own masks to determine where to pay attention
Note posted on Saturday, September 23, 2023 6:19 PM CDT - link
Automated Project Publishing
The idea: a small script that periodically runs, checking for changes to project readme's, and publishes updates to davidvedvick.info.
This script would need to reside in a-personal-site. Would need to be configurable so that it could accurately be run on a local machine but also on a build server.
Update 11/28/2023: I instead implemented this as GoCD pipeline that I run on-demand, and it is glorious.
Note posted on Friday, September 22, 2023 7:17 PM CDT - link
July 30th, 2023
Programming Proficiency
To solve programming problems reliably one needs two skills:
- Proficiency in set theory.
- Specifying the correct behavior of code in tests.
Organization (naming things, type hierarchies, module placement) is also extremely useful for ensuring code maintainability, but it is a tangential skill to the first two skills.
Note posted on Sunday, July 30, 2023 9:08 PM CDT - link
June 9th, 2023
The pareto rule strikes again - employees are at their best when they're working at 85% capacity, not 100% - https://hbr.org/2023/06/to-build-a-top-performing-team-ask-for-85-effort.
Note posted on Friday, June 9, 2023 7:42 AM CDT - link
May 28th, 2023
Most dependencies are just data. Data "repositories" are easier to fake than mock. Maybe mocks should just be used for hardware I/O?
Note posted on Saturday, May 27, 2023 7:17 PM CDT - link
Open Source 2023 Notes
Inside ChatGPT
- Lab651 and Recursive Awesome, Captovation - AI Solutions Development
- Applied AI - 501c3 organization
GPT Releases
- Version 1 - 117M parameters
- Version 2 - 1.5B parameters
- Version 3 - 175B parameters
- Version 4 - 1T+ parameters
Wolfram One
- Cloud/desktop hybrid, integrated computation platform
- Similar to Jupyter notebooks
- Lets you play around with GPT models (older than v3 and v4)
GPT 2
Always using the next highest probability word isn't always the best... using a "temperature" parameter, the model can be tweaked to sometimes choose words that aren't quite the highest probablity, leading to fewer run-on sentences.
Attention - when the model picks up on a higher probability and begins to focus in on it
Embeddings - training model on relationships between words (word pairs in a sense)
- Example: Munich - Berlin + France => Paris
- This can also be done for sequences of words and whole blocks of text
ChatGPT has learned syntactic grammar using embedding techniques
- When determing a sequence of words, it essentially follows a random walk through the syntactic grammar
Wolfram can break down the structure
OpenAI playground: https://platform.openai.com/playground
"How would you create a neural network model that would rule the world? Please write it out in small, specific steps."
Stable Diffusion
- "Speaking plainly" to computers -isn't this programming?
- Hannah Loegering - @fractalorange
- Open Source AI:
- Deforum (Video, Image)
- Automatic1111/stale-diffusion-webai
- Langchain
- Simulacra and Simulation
- GPT4All Chat (text)
- Flowise/langchainJA-ui
- @secondsightvisuals
- Music is a 4-dimensional dataspace
- Replicate - lucid sonic dreams, takes a source and produces an infinite sequence
- phygital+ - create 3d-printed models
- Can download stale diffusion and run locally
- Midjourney runs over discord?
- Luma AI - create 3D scenes and scan from 2D video
- Kaiber - super easy AI animation
- Wonder Dynamics - 3D character repalcement in 2D video
- Deep Motion - 3D character rigging from 2D video
- Runway ML - Full suite of video tools including their Gen1 and Gen2
- Blockade Labs: text to 360 image
- Simulacra - build 3D assets
Role of Generative AI in Healthcare
- CTO of Virtuwell (Telehealth)
- Virtuwell is not-for-profit?!
Care Delivery
- Diagnosis prediction
- Support clinicians by providing relevant medical info
- Personalized health and wellness advice to individuals
Medicine
- Personalized medicine: Forecast outcomes via patterns
- Drug Discovery: identify possible new meds and predict compounds likely to be effective
Health Plan
- Organize unstructured medical data
Virtuwell AI initiatives
- Reduce over/under staffing by predicting the future
- Predict surge traffic to website
- Analyze patient data for systematic follow ups
- Funneling relevant medical records
- At-home kit for colon cancer screening and STI
Healthcare Companies in AI
- Optellum: rules out harmless cases of lng canver via scans.
- Ultromics: increases diagnostic accuracy of coronary heart disease from 80% to 94%
- IDx-DR (now Digital Diagnostics): correctly identifies diabetic retinopathy by 87.4% (8% better than industry standard)
- Beyond Verbal: Detecting Coronary Artery Disease by listening to voice
Future of Generative AI
- If you are a large enterprise, you need to train your own LLM
Under-Engineering
- Information / Technology impedance
- Programmers making wrong asusmptions based on limited informaiton
- Tribal knowledge lost over time and developer turnover
- Lack of documentation
- Code not self-documenting
- Unreadable unit tests
- Distance between code and documentation (documentation is on a remote server away from source)
- Self-inflicted complexity
- Ineffective bootstrapping: programmers bringing in their own toolsets instead of assessing what tools are best for their projets
- Programmers building their own frameworks
- Overfitting
- Bug-fixes / rework
- Bandaging code quickly instead of reworking code complexity
- Under-engineering: act of explicitly engineering in a simplistic manner
- Architecture should be as simple as possible
- Developer documentation should be simple and accessible (developers should have their own set of documentation)
- Coding should be simple, readable, and maintainable
Reduce Complexity
- Find the most confusing concepts o fthe codebase
- Document Confusion
- Unit tests should be your guide on refactors
- Unit tests should be user friendly
- Reverse code entropy - deleting code??
- Identify:
- Challenging developer cadences
- confusing folder structures
- Hard-to-read / hard-to-write code
- Bad model or variable names
- Put documentation next to code
- Design for NOW, but with the future in mind
- Ask what-if, but don't design for what-if in order to ensure you don't box yourself out
- Push back on product feature work
- Use 90% rule for generic/inheritance patterns
- Provide code samples
- Write comments first? (why not write unit tests first? :P)
IOT Eventing
General Workflow
Devices -> Event Ingestion -> Event Matching -> Event Delivery -> Event Actions -> Back to Device(s)
Design Constraint: Event Volume
- Devices/Locations = 100
- Max Events per Device: 10 events/s
- SLO: < 1s response time from client controllers to devices
Evolution of Eventing
- 2011 - Monolithic, event-based architecture built around RabbitMQ
- 2013 - Monolith + sharding
- 2015 - Microservices: strong REST principles instead of Event Oriented Architecture, using Kafka instead of RabbitMQ
- 2015-2019 - Event pipeline: Kafka, Amazon EC2, SQS, oh my...
- 2019-current: one suscription system instead of a subscription per device type
- Move to a stateful subscription model
- One users events will always go through the same box
- Makes latency stable
- Breaking down and logically dividing up work wihtin a system is critical
Note posted on Tuesday, May 23, 2023 7:17 PM CDT - link
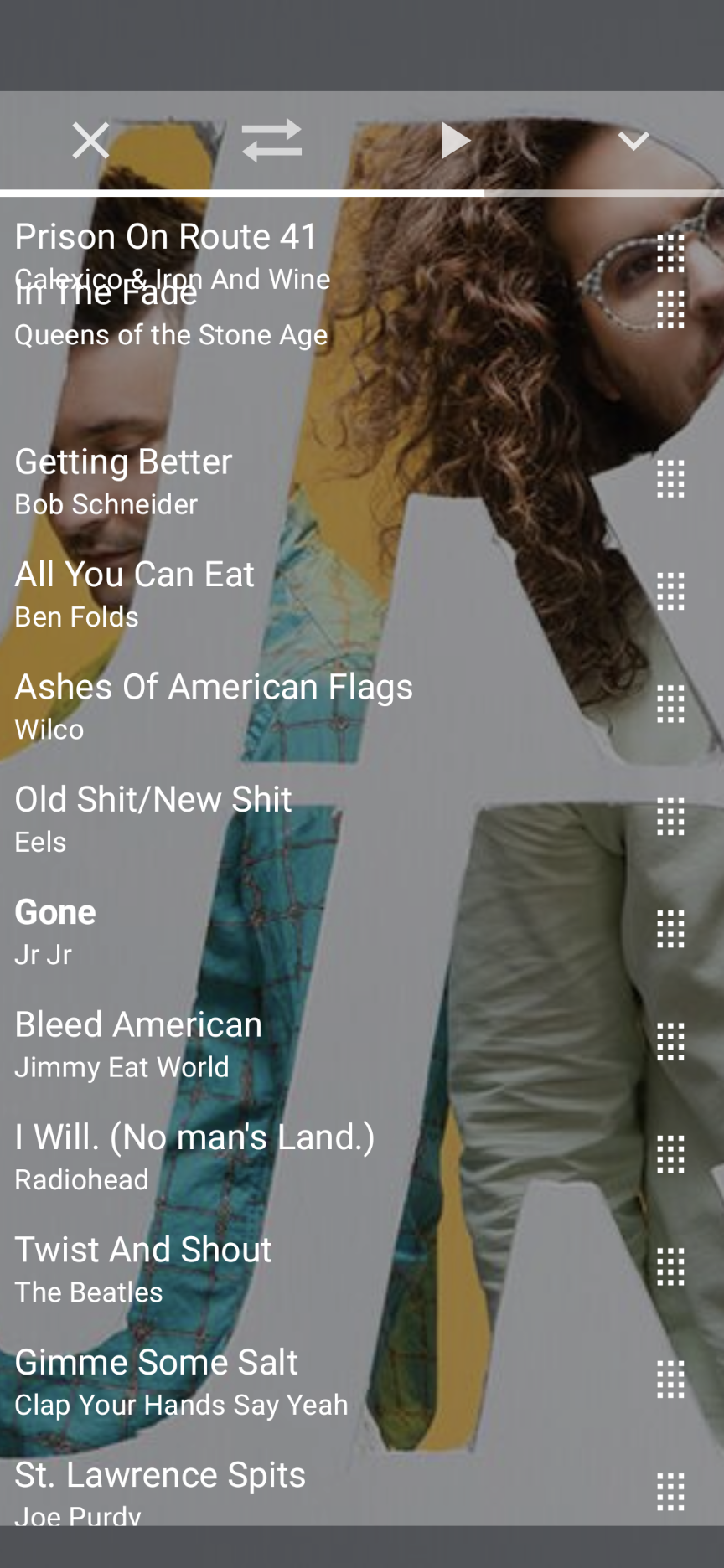
Drag And Drop Difficulties
It is surprisingly difficult to get drag and drop working in jetpack compose. I have had it working in most parts of the list for most of the week, but the first element causes the LazyList to readjust its bounds, causing absolute chaos. A fix I discovered in Google's examples partially helps, but still leaves the dragged element in limbo:
Note posted on Thursday, April 27, 2023 6:56 AM CDT - link